
Invatam sa facem un model cu Scikit-Learn
Sa facem un model de ML de la 0 consuma foarte mult timp si este complex. Scikit-Learn care este o biblioteca open-source din Python care ne ajuta sa facem mai usor un model de ML. Aceasta ofera o interfata simpla si consecventa pentru sarcini precum clasificarea, regresie, clusterizare, preprocesarea datelor si evaluarea datelor. Este utila atat pentru incepatori, cat si pentru persoane cu exeperienta in domeniu permitand construirea rapida a unor modele fiabile.
De ce sa folosim Scikit-learn?
Scikit-learn ofera instrumente pentru preprocesare, antrenare si evaluare.
Accepta schimbarea usuara a algoritmilor si reglarea hiperparametrilor.
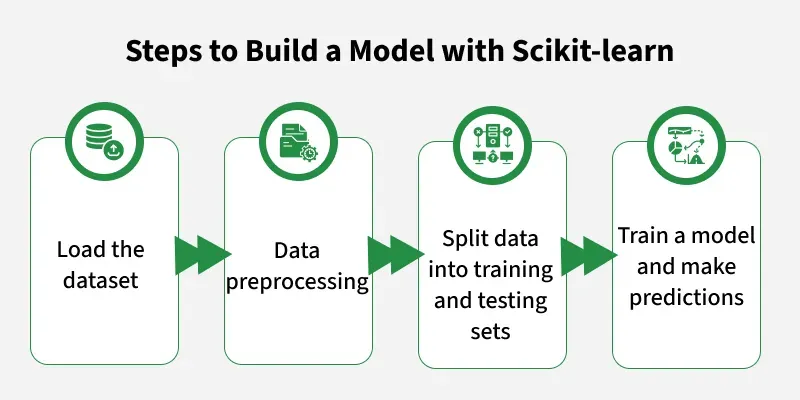
1.Incarca setul de date
Iti aduci datele in memorie dintr-o sursa (CSV, SQL, Parquet) sau folosesti un set de date inclus în Scikit-learn. Identifici variabila tinta (ce vrei sa prezici) si caracteristicile (predictorii). Faci o privire rapida pentru a depista valori lipsa, distributii dezechilibrate sau erori evidente.
2.Preproceseaza datele
Transformi datele brute in format potrivit modelarii: tratezi valorile lipsa, codezi variabilele categorice, scalezi numericile și, la nevoie, creezi trasaturi noi. Cel mai sigur este sa pui totul într-un Pipeline/ColumnTransformer, astfel încat pasii sa fie aplicati corect doar pe datele de antrenare, evitand scurgerea de informație.
3.Imparte datele in seturi de antrenare si testare
Separi un esantion pentru evaluare finala, de obicei 20–30% pentru test. Pentru clasificare, folosește stratify=y ca sa pastrezi proporția claselor. Pentru selectia si reglarea modelelor, ia în calcul validarea incrucisată (ex. StratifiedKFold) pe setul de antrenare.
4.Antreneaza un model si realizeaza predictii
Alegi un algoritm potrivit (de ex. LogisticRegression, RandomForestClassifier, XGBClassifier,LinearRegression pentru regresie). Il "potrivesti” pe datele de antrenare, faci predictii, apoi evaluezi cu metrici adecvate (acuratete, F1/AUC la clasificare; MAE/MSE/R² la regresie). Optimizezi hiperparametrii cu cautari sistematice, ideal in combinatie cu un Pipeline.
Cum sa instalam si sa folosim Scikit-learn?
Inainte sa incepem sa construim modele trebuie sa instalam Scikit-learn. Aceasta necesita biblioteca Python 3.8 sau o versiune mai noua si depinde de doua biblioteci importante: NumPy si SciPy. Asigura-te ca acestea sunt instalate mai intai.
Pentru a instala Scikit-learn, ruleaza urmatoarea comanda "pip-install -U scikit-learn"
Aceasta va descărca și instala cea mai recentă versiune de Scikit-learn împreună cu toate dependențele necesare. Acum haideti sa vedem pasii implicati in procesul de construire a unui model folosind biblioteca Scikit-learn.
Pasul 1: Incarcarea unui set de date
Un set de date este o colectie de informatii folosita pentru a antrena si testa modelele de invatare automata. Are doua parti principale:
Features: numite si predictori sau intrari - variabilele care descriu datele. Pot exista mai multe caracteristici, reprezentate ca o matrice de caracteristici notata cu "X". Lista tuturor denumirilor caracteristicilor este cunoscuta sub numele de feature names.
Response: numit si tinta, eticheta sau iesire - variabila pe care dorim sa o precizam. Este o singura coloana, reprezentata ca un vector de raspuns notat cu "Y", iar toate valorile posibile pe care le poate lua acest vector sunt numite target names.
Scikit-learn ofera cateva seturi de date de exemplu care pot fi folosite pentru a invata si testa algoritmi de invatare automata. Printre acestea se numara seturile de date Iris si Digits pentru sarcini de clasificare, precum si setul de date Boston Housing pentru sarcini de regresie.
Pentru a folosi seturi de date Iris:
"load_iris()" - incarca setul de date Iris in variabila iris
Features si Targets: X contine datele de intrare (caracteristici precum lungimea petalei, latimea etc.), iar Y contine valorile tinta (speciile de floare iris)
Nume: features_names si target_names ofera numele caracteristicilor si ale etichetelor tinta
Inspectarea datelor: afiseaza numele caracteristicilor si ale tintelor, verifica tipul lui X si afiseaza primele 5 randuri din datele caracteristicilor pentru a intelege structura
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
print("Feature names:", feature_names)
print("Target names:", target_names)
print("\nType of X is:", type(X))
print("\nFirst 5 rows of X:\n", X[:5])In consola o sa vedem:

Uneori trebuie sa lucram cu propriile noastre date personalizate, apoi incarcam un set de date extern. Pentru acest lucru putem folosi biblioteca pandas pentru incarcarea si manipularea usoara a seturilor de date.
Pasul 2: Impartirea setului de date
Este important sa impartim un set de date in seturi de antrenare si testare pentru a evalua eficient performanta modelului. Setul de antrenare este folosit pentru a invata modelul, iar setul de testare ajuta la evaluarea modului in care modelul functioneaza pe date noi, nevazute anterior.
In Scikit-learn, putem folosi functia train_test_split din modulul sklearn.model_selection. De exemplu, folosind setul de date Iris, putem aloca 60% din date pentru antrenare si 40% pentru testare, specificand random_state=1 pentru a asigura reproductibilitatea. Dupa impartire, se creeaza patru subseturi:
X_train si y_train: caracteristicile si valorile tinta folosite pentru antrenarea modelului.
X_test si y_test: caracteristicile si valorile tinta rezervate pentru testare.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1)Acum sa verificam formele (Shapes) datelor impartite (Splitted Data) pentru a ne asigura ca ambele seturi au proportii corecte de date, evitand orice posibile erori in evaluarea sau antrenarea modelului.
print("X_train Shape:", X_train.shape)
print("X_test Shape:", X_test.shape)
print("Y_train Shape:", y_train.shape)
print("Y_test Shape:", y_test.shape)In consola o sa vedem:

Pasul 3: Gestionarea datelor categorice
Algoritmii de invatare automata necesita date numerice, asa ca este important sa gestionam corect datele categorice. Daca variabilele categorice raman sub forma de text algoritmii le pot interpreta gresit, ceea ce duce la rezultate slabe. Pentru a evita acest lucru, transformam datele categorice in forma numerica folosind tehnici de codificare:
1.Codificare prin etichete (Label Encoding): Transforma fiecare categorie intr-un numar intreg unic. De exemplu, intr-o coloana cu categorii precum "pisica", "caine" si "pasare", acestea ar fi transformate in 0, 1 si respectiv 2. Aceasta metoda functioneaza bine atunci cand categoriile au o ordine semnificativa cum ar fi "Scazut", "Mediu" si "Ridicat"
"LabelEncoder()": Este initializat pentru a crea un obiect encoder care va transforma valorile categorice in etichete numerice
"fit_transform": Aceasta mai intai potriveste encoderul pe datele categorice, apoi transforma categoriile in etichete numerice corespunzatoare.
from sklearn.preprocessing import LabelEncoder
categorical_feature = ['cat', 'dog', 'dog', 'cat', 'bird']
encoder = LabelEncoder()
encoded_feature = encoder.fit_transform(categorical_feature)
print("Encoded feature:", encoded_feature)In consola o sa vedem:
Encoded feature: [1 2 2 1 0]
2.Codificare One-Hot (One-Hot Encoding)
Aceasta tehnica creeaza coloane binare pentru fiecare categorie, unde fiecare coloana reprezinta o categorie. De exemplu, daca o coloana are valorile "pisica", "caine" si "pasare", se vor crea trei coloane noi, cate una pentru fiecare categorie. Fiecare rand va avea valoarea 1 in coloana corespunzatoare categoriei sale si 0 in celelalte. Aceasta metoda este utila pentru variabile categorice care nu implica relatii numerice intre categorii.
OneHotEncoder: Asteapta ca datele de intrare sa fie intr-un tablou bidimensional (2D), adica fiecare esantion sa fie un rand si fiecare caracteristica sa fie o coloana. Din acest motiv, datele trebuie remodelate.
OneHotEncoder(sparse_output=False): Creaza un obiect encoder care va transforma variabilele categorice in coloane binare.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
categorical_feature = ['cat', 'dog', 'dog', 'cat', 'bird']
categorical_feature = np.array(categorical_feature).reshape(-1, 1)
encoder = OneHotEncoder(sparse_output=False)
encoded_feature = encoder.fit_transform(categorical_feature)
print("OneHotEncoded feature:\n", encoded_feature)In consola o sa vedem:

Pasul 4: Antrenarea modelului
Acum ca datele noastre sunt pregatite, este momentul sa antrenam un model de invatare automata. Biblioteca Scikit-learn ofera numerosi algoritmi cu o interfata unitara pentru antrenare, predictie si evaluare. Aici vom folosi Regresia Logistica ca exemplu.
Nota: Nu vom intra in detalii despre modul in care functioneaza algoritmul, deoarece ne intereseaza doar implementarea lui.
log_reg = LogisticRegression(max_iter=200): Creeaza un obiect clasificator de regresie logistica.
log_reg.fit(X_train, y_train): Folosind aceasta instructiune, modelul de regresie logistica isi ajusteaza parametrii pentru a se potrivi cat mai bine datelor.
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression(max_iter=200)
log_reg.fit(X_train, y_train)Pasul 5: Realizarea predictiilor
Odata ce modelul a fost antrenat, il folosim pentru a face predictii pe datele de test X_test apeland metoda predict. Aceasta returneaza etichetele prezise y_pred.
log_reg.predict: Foloseste modelul de regresie logistica antrenat pentru a prezice etichetele pentru datele de test X_test.
y_pred = log_reg.predict(X_test)Pasul 6: Evaluarea acuratetii modelului
Verifica cat de bine functioneaza modelul nostru comparand y_test si y_pred. Aici folosim metoda accuracy_score din modulul metrics.
from sklearn import metrics
print("Logistic Regression model accuracy:", metrics.accuracy_score(y_test, y_pred))In consola o sa vedem:
Logistic Regression model accuracy: 0.9666666666666667
Esantionul de intrare poate fi transmis in acelasi mod ca o matrice de caracteristici. Exemplu de date de intrare: sample = [[3, 5, 4, 2], [2, 3, 5, 4]]
sample = [[3, 5, 4, 2], [2, 3, 5, 4]]
preds = log_reg.predict(sample)
pred_species = [iris.target_names[p] for p in preds]
print("Predictions:", pred_species)In consola o sa vedem:
Predictions: [np.str_('virginica'), np.str_('virginica')]